This is a necropost, resurrected from an old blog.
The hack
The Parliamentary Hack, recently featured in the Independent, was an interesting event. Almost every age group was represented and the event was a hive of activity from the word go.
Hack days (this was a weekender) are popular amongst data geeks, design geeks, and coders. They serve as a very sociable way to get together and create cool stuff under pressure, and that’s fun! The idea is simple: hack up something cool from the data available in 36 hours. Work with whoever you like, join teams, leave teams, work solo, and whatever you create: present it at the end for the possibility of a prize.
Working with a few folks (we called ourselves Team Whip), we settled on a project: Champion - a service that parses debates from parliament and using that data allows you to search for MPs that care about the things you do. The data we settled on was a pre-parsed set of XML representing the Hansard data, and a few other supplimentary sources.

Analysing MPs
Our analysis looked at all the parliamentary debates since the last election. We pulled out frequencies of term usage to help detect what MPs were talking about, and made the results searchable so that users could type some simple keywords declaring their interests, and get back MPs ranked by just how much they’d talked about those things. It’s a crude measure of how much they share that interest.
This is harder than it sounds for quite a few reasons. Words are easy to search for, but many words appear in different forms - so you can’t just do a plain-text search.
For instance, how do I find an MP who talks about nursing?
In the data set we’re using the word nursing appears a few times, as does the word nurse, as does the word nurses. In samples of the size we’re looking at, you might easily miss the most appropriate MP if you performed a strict word search on just one of these terms.
Instead, we decided to analyse the data first and retrieve information about terms – and this is where the Topia library makes its debut.
Topia.TermExtract is a utility that does some very interesting things, the result of which means that words like nurses, nursing, and nurse all condense to nurse; and other words that are obvious groupings (Metropolitan Police) are delivered as a grouped term.
Colleague and friend Giuseppe worked hard on this while I built a user interface for it.
The UI
The UI was the typical HTML/css/javascript combo using Bootstrap and jQuery to spruce it up, and stitch it together. Why? Because it’s fast and easy to knock out prototypes that interact well with standard services. We wanted to build some very clear, straightforward interactions as quickly as possible, and this was an opportunity to really focus on the user.
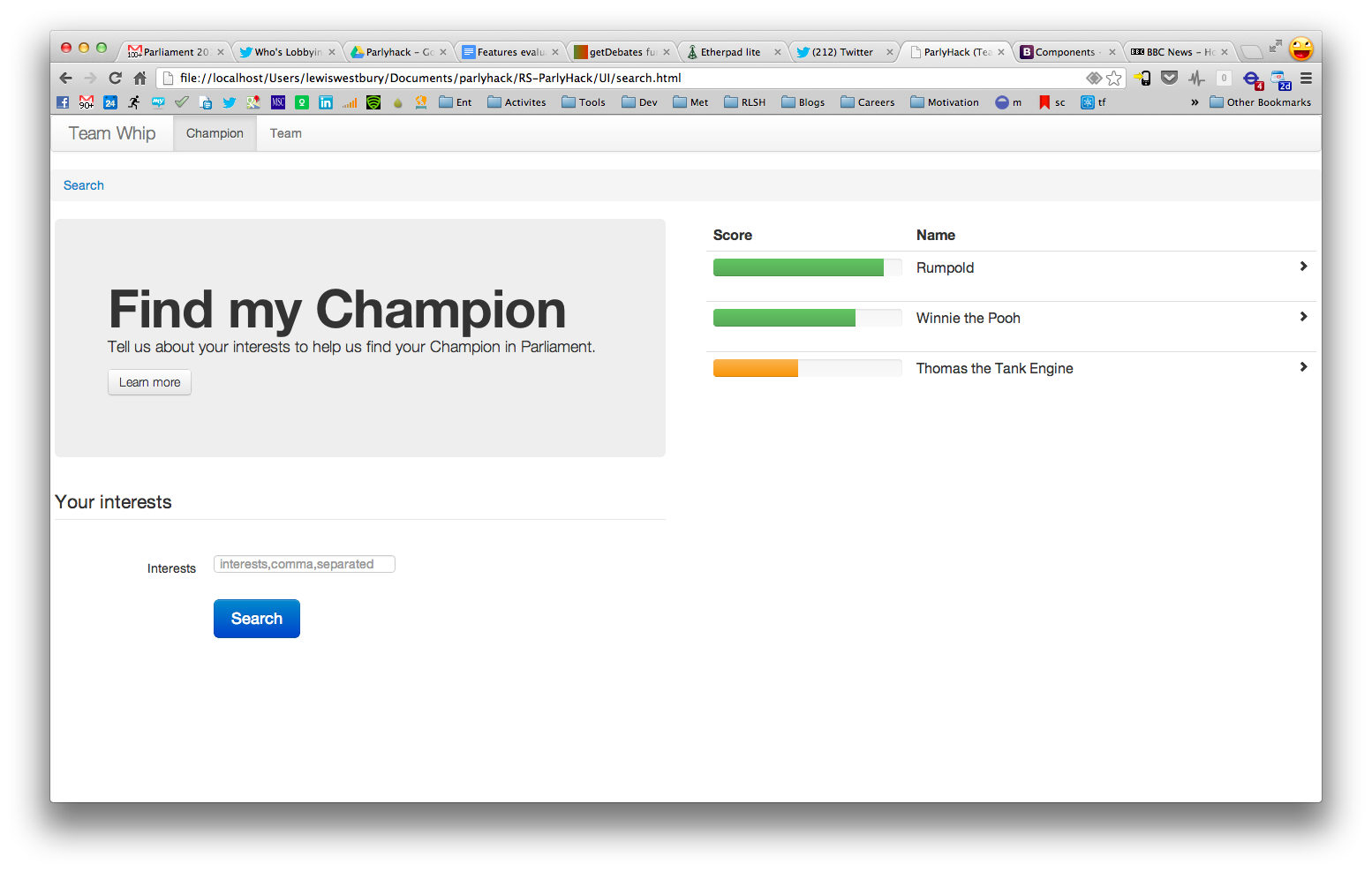
The UI evolved pretty fast - and iterative development is the key here if you want something attractive and easy to use. We worked with colleagues producing copy (Hadley - data geek), designs (Sharon - design geek), and tea (Mark - team geek) - and integrating all those disparate skills gave us a real edge (and the capacity to achieve what we needed very quickly).
In 36 hours, that’s about as far as you can go. You can try out Champion today. I’m pleased to say we won Best in Show for our efforts, and you can read about the hack in the Independent.
Where now?
This hack is something we’re planning to take forward, and there are some significant shortfalls of the approach we’ve taken (that I’m sure will occur to you) that we want to address. Giuseppe is interested by the possibilities of Latent Dirichlet Allocation (LDA) - a statistical analysis tool for deriving the blends of topics in a document.
- Sometimes, an MP may be participating in a debate on a given topic without saying any of the magical keywords. He or she may be talking about a colleague’s attitudes or some other tangent. In order to detect these contributions we’d probably want to look at the debate as a whole - derive the topics it contains using LDA - and then give MPs a score for their contribution based on length (and relevance if we can evaluate that).
- Now, simply because you talk about something a lot doesn’t mean you care about it the same way the user does. We’d also like to do some sentiment analysis on the text to determine just how MPs feel about subject - or what they have to say on the matter.
- Of course, MPs are particularly slippery fish to catch. You may find that the more wonderful the hospital sounds in their grand speeches the more utterly they’ve closed it tomorrow. It’s possible we can do some further analysis and contribute to our scoring systems by looking for other things - accusations in debates perhaps, and media reports - that can help us to identify their intent more appropriately.
